Building Agentic AI Infrastructure: Why Your 2020 Stack Can't Keep Up in 2026
You can't bolt autonomous agents onto legacy REST APIs and expect magic. Here's the infrastructure redesign that actually works.

This article was originally published on Medium
The Agentic AI Paradox: Everyone’s talking, few are succeeding
Agentic AI dominates every enterprise technology conversation. Conference keynotes promise autonomous systems that will revolutionize operations. Vendor pitches showcase agents that handle customer service, process documents, manage workflows, and make decisions.
There’s no shortage of pilot projects. Every enterprise has at least one team experimenting with agents. Innovation labs are full of promising demos. Proof-of-concepts work beautifully in controlled environments with curated data. But ask about agents running in production, handling real customer load, making decisions without human oversight — and the success stories become remarkably scarce.
The default assumption is that these are AI problems — the models aren’t good enough, the training data isn’t comprehensive enough, the prompts aren’t optimized enough. Teams respond by switching models, tuning parameters, hiring prompt engineers, and running more experiments.
They’re solving the wrong problem. The models are fine. The infrastructure is broken.
Here’s the fundamental mismatch: Our current infrastructure was designed for request-response patterns where humans click buttons and wait for results. Agentic workflows are fundamentally different — they need to orchestrate work across multiple systems, handle failures gracefully, maintain context across hours or days, and make decisions based on changing conditions. You can’t force that pattern into a thirty-second timeout window without breaking something essential.
The gap isn’t about AI advancement. It’s about infrastructure evolution.
Let’s talk about what should be done.
Pillar 1: Semantic Telemetry — Making Errors Machine-Readable
Your current monitoring stack is optimized for humans. Dashboards turn red, error rates spike, someone gets paged at 2 a.m. A senior engineer logs in, reads through logs, connects the dots based on years of experience, and deploys a fix. This works when humans are in charge to fix an issue. It fails catastrophically when agents need to diagnose and fix problems on their own.
The problem is deceptively simple: traditional error messages reference internal system states that mean nothing without institutional knowledge. A payment system fails and logs “Error 500: Internal server error.” An experienced engineer knows that probably means the payment gateway is down, knows to check recent deployments, maybe knows to restart a specific service based on the time of day. An agent sees structured data that says “something broke somewhere” with no actionable path forward.
Think about what agents need instead. When a payment fails, they need to know: what specific capability is broken? (Payment processing through our primary vendor). What options exist to fix it? (Retry with exponential backoff, or fail over to our backup payment processor). How confident should I be in each option? (Failover is 94% likely to work within 4 seconds, retry is 86% likely to work within 20 seconds). What’s the business impact? (Customer is blocked at checkout with $247.50 in their cart, waiting for 2 minutes already).
Here’s what this looks like in practice. Traditional error log:

Semantic telemetry for the same error:
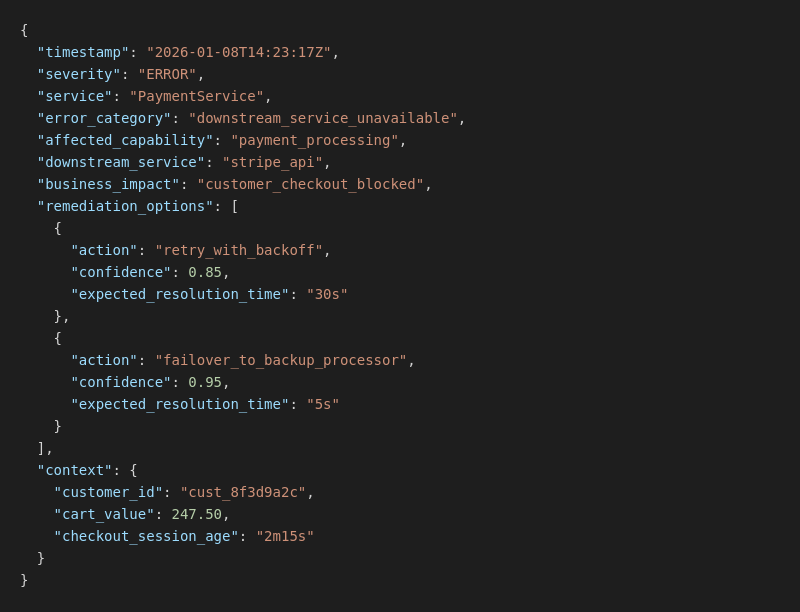
The second version isn’t just more detailed. It’s machine-readable decision support. The agent knows what broke, what business capability is affected, what actions are available with confidence scores, and what business context matters for prioritization.
The ROI is immediate and measurable in this case. Consider a fintech company that implements semantic telemetry. Their mean time to resolution for common failure modes could drop from minutes to seconds. Not because their engineers got faster — they wouldn’t touch most of these incidents anymore. Agents could read the semantic error context, evaluate remediation options based on confidence scores, execute the fix, and log the decision for human review later.
This is the infrastructure foundation that makes agent self-healing possible. Without machine-readable context about what broke and how to fix it, agents are flying blind.
Pillar 2: Event-Driven Architecture for Agent Workflows
Synchronous APIs aren’t just slow for agents — they’re architecturally incompatible with how autonomous systems need to work. The problem isn’t performance. It’s the fundamental assumption that operations complete quickly enough to hold a connection open and wait.
Consider a procurement workflow. An agent needs to source office supplies, get quotes from multiple vendors, route to the appropriate manager for approval, and place the final order. In a synchronous architecture, this looks like a series of blocking calls: call vendor API and wait, call pricing API and wait, call approval system and wait… indefinitely while a human manager reviews the request over their morning coffee.
Your systems timeout after thirty seconds. The manager approves the purchase three hours later. The agent has long since given up, lost all context about what it was doing, and requires human intervention to restart the entire process from scratch.
Traditional infrastructure assumes all operations complete in seconds. Agentic workflows span minutes, hours, or days. You can’t keep a connection alive while waiting for human approval cycles. You need infrastructure that treats long-running processes as expected behavior.
Event-driven architecture solves this by completely decoupling the initiation of work from its completion. The agent publishes events to a message bus, subscribes to responses, and maintains state across arbitrary time spans. When the approval comes back three hours later, the agent picks up exactly where it left off — with full context about the vendors it contacted, the quotes it received, and the business justification for the purchase.
Think of it like this: In synchronous architecture, the agent is on the phone waiting for someone to answer. After thirty seconds, the call drops. In event-driven architecture, the agent sends an email and subscribes to responses. Whether the reply comes back in thirty seconds or three hours makes no difference — the agent processes it when it arrives, with full context from the original request.
The business impact compounds. When agents can reliably orchestrate multi-day workflows without human intervention, you can automate processes that were previously impossible to automate. Not because the AI got smarter, but because the infrastructure stopped breaking.
Pillar 3: Metadata Layer — Context Over Clean Data
The “clean data” obsession killed more agentic projects in 2025 than any other single belief. Teams spent months cleaning data, normalizing database schemas, ensuring referential integrity — doing everything the textbooks said to do. Then they handed these pristine, beautifully normalized tables to their agents and wondered why the results were terrible.
Here’s what they missed: Agents don’t need clean data. They need contextual data. The difference is fundamental.
Consider a customer record in your CRM. A clean database would show: customer ID, name, email address, account tier, account creation date. Perfect data hygiene. Completely useless for an agent trying to decide how to handle a customer interaction.
What the agent actually needs: This customer has exhibited price sensitivity in the past (chose cheaper options three out of their last four purchases). They prefer email communication (90% email response rate vs. 20% for phone calls). They have an open support ticket about a billing discrepancy that’s been escalated once already. They qualify for enterprise discount programs based on their purchase volume but haven’t been offered them yet. They’re showing early warning signs of churn (login frequency dropped 60% in the last month).
None of that context lives in a clean customer table. It lives in the relationships between data, the patterns in historical behavior, the business rules about eligibility and risk, and the operational metadata about current state. This is what I mean by a metadata layer — not just storing data, but storing what that data means in business terms.
For AI systems doing retrieval (pulling relevant information to answer questions), metadata is the difference between accurate results and accurate-sounding wrong results. When an agent retrieves company policy documents, it needs to know: Is this policy binding or advisory? Is it current or superseded by a newer version? Does it apply to this employee type in this situation? What are the compliance implications?
Without that metadata, agents retrieve text that sounds relevant but might be outdated policy, might apply to a different employee category, might be advisory guidance being treated as mandatory requirements. With metadata, agents retrieve the right information with the right level of authority.
The fundamental shift required: Stop thinking about data quality in terms of cleanliness and start thinking about it in terms of context richness. Your agents need to understand not just what the data says, but what it means for business decisions.
Pillar 4: Avoiding the Bespoke Agent Trap
There’s a pattern emerging in 2025 that should terrify anyone responsible for enterprise architecture: every department is building their own agents on their own infrastructure. Marketing has their content generation agent. Finance has their reconciliation agent. HR has their recruiting agent. Sales has their lead qualification agent.
Each one works beautifully in isolation. Each one is a maintenance nightmare. Each one creates technical debt that will take years to pay down.
This is shadow IT 2.0. Instead of teams spinning up rogue SaaS subscriptions, they’re spinning up entire AI infrastructure stacks. The problems compound predictably:
Finance’s agent can’t talk to HR’s agent because they use different event formats and state management approaches. When you need to update security policies, you have to coordinate changes across eight different agent implementations, each built by teams whose primary expertise is their business domain, not infrastructure engineering. Observability is fragmented because there’s no unified way to monitor what agents are doing. Audit trails are inconsistent because each team implemented their own compliance logging. Error handling varies wildly in quality because everyone reinvented retry logic and failure recovery.
You’re solving similar problems eight times with eight different solutions, none of them particularly robust because they’re all side projects for teams focused on their domain expertise.
The solution is platform thinking. Build universal agent infrastructure once, centrally, with proper engineering rigor. Then let domain teams deploy agents that focus purely on business logic, inheriting all the infrastructure capabilities automatically.
Think of it like internal developer platforms for traditional software. You don’t let every team build their own Kubernetes clusters, design their own CI/CD pipelines, and implement their own secrets management. You build shared infrastructure that handles all of that complexity, then teams deploy applications that inherit those capabilities.
The same principle applies to AI agents. When Finance builds their reconciliation agent, they should inherit: automatic state persistence so workflows survive restarts, semantic telemetry so errors are machine-readable, audit trails for compliance, security controls for data access, and standardized error handling. They focus on reconciliation logic. The platform handles everything else.
When your platform provides better state management, better observability, better security, and faster time-to-production than anything teams could build themselves, adoption becomes natural rather than mandated. When the platform handles infrastructure complexity, domain teams ship value faster and with higher quality than when they’re reinventing infrastructure on the side.
The Real Challenge Isn’t AI — It’s Architecture
The infrastructure gap between what AI agents need and what our current systems provide is real and widening. Your 2020 stack was architected for human operators clicking through web interfaces, not autonomous systems orchestrating complex workflows.
The companies winning with AI agents in 2026 aren’t the ones with access to the latest foundation models. Those models are largely commoditized. The winners are the ones who rebuilt their infrastructure to support autonomous operation. They invested in making errors machine-readable, workflows durable across time, and data contextually rich.
The technology gap isn’t widening because AI is advancing too quickly for infrastructure to keep up. It’s widening because most organizations are trying to bolt AI agents onto infrastructure that was never designed for autonomous operation.
Time to rebuild for what comes next.